# CogVLM 最佳实践
## 目录
- [环境准备](#环境准备)
- [推理](#推理)
- [微调](#微调)
- [微调后推理](#微调后推理)
## 环境准备
```shell
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
```
## 推理
推理[cogvlm-17b-chat](https://modelscope.cn/models/ZhipuAI/cogvlm-chat/summary):
```shell
# Experimental environment: A100
# 38GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift infer --model_type cogvlm-17b-chat
```
输出: (支持传入本地路径或URL)
```python
"""
<<< Describe this image.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/cat.png
This image showcases a close-up of a young kitten. The kitten has a fluffy coat with a mix of white, gray, and brown colors. Its eyes are strikingly blue, and it appears to be gazing directly at the viewer. The background is blurred, emphasizing the kitten as the main subject.
--------------------------------------------------
<<< clear
<<< How many sheep are in the picture?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png
There are four sheep in the picture.
--------------------------------------------------
<<< clear
<<< What is the calculation result?
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/math.png
The calculation result is '1452+45304=45456'.
--------------------------------------------------
<<< clear
<<< Write a poem based on the content of the picture.
Input a media path or URL <<< http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/poem.png
In a world where night and day intertwine,
A boat floats gently, reflecting the moon's shine.
Fireflies dance, their glow a mesmerizing trance,
As the boat sails through a tranquil, enchanted expanse.
--------------------------------------------------
<<< clear
<<< Perform OCR on the image.
Input a media path or URL <<< https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/ocr_en.png
The image contains textual content that describes the capabilities and features of the SWIFT framework. It mentions support for training, inference, and deployment of 250+ LLMs and 35+ MLMs, and how developers can apply this framework to their research and production environments. It also mentions lightweight training solutions provided by PEFT and an adapter library to support the latest training techniques. Additionally, the text highlights that SWIFT offers capabilities for other modalities and supports full-parameter training and LLaMA training for AnimateDiff. There's also a mention of rich documentation available on Huggingface space and ModelScope studio.
"""
```
示例图片如下:
cat:
 animal:
animal:
 math:
math:
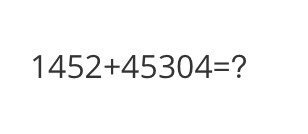 poem:
poem:
 ocr_en:
ocr_en:
 **单样本推理**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.cogvlm_17b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: From Mata, it is 14 km; from Yangjiang, it is 62 km; and from Guangzhou, it is 293 km.
query: Which city is the farthest?
response: Guangzhou is the farthest city with a distance of 293 km.
"""
```
示例图片如下:
road:
**单样本推理**
```python
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from swift.llm import (
get_model_tokenizer, get_template, inference, ModelType,
get_default_template_type, inference_stream
)
from swift.utils import seed_everything
import torch
model_type = ModelType.cogvlm_17b_chat
template_type = get_default_template_type(model_type)
print(f'template_type: {template_type}')
model, tokenizer = get_model_tokenizer(model_type, torch.float16,
model_kwargs={'device_map': 'auto'})
model.generation_config.max_new_tokens = 256
template = get_template(template_type, tokenizer)
seed_everything(42)
images = ['http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/road.png']
query = 'How far is it from each city?'
response, _ = inference(model, template, query, images=images)
print(f'query: {query}')
print(f'response: {response}')
# 流式
query = 'Which city is the farthest?'
images = images
gen = inference_stream(model, template, query, images=images)
print_idx = 0
print(f'query: {query}\nresponse: ', end='')
for response, _ in gen:
delta = response[print_idx:]
print(delta, end='', flush=True)
print_idx = len(response)
print()
"""
query: How far is it from each city?
response: From Mata, it is 14 km; from Yangjiang, it is 62 km; and from Guangzhou, it is 293 km.
query: Which city is the farthest?
response: Guangzhou is the farthest city with a distance of 293 km.
"""
```
示例图片如下:
road:
 ## 微调
多模态大模型微调通常使用**自定义数据集**进行微调. 这里展示可直接运行的demo:
```shell
# Experimental environment: A100
# 50GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm-17b-chat \
--dataset coco-en-2-mini \
```
[自定义数据集](../Instruction/自定义与拓展.md#-推荐命令行参数的形式)支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 但总的轮次对话只能包含一张图片, 支持传入本地路径或URL)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]], "images": ["image_path"]}
```
## 微调后推理
直接推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora**并推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```
## 微调
多模态大模型微调通常使用**自定义数据集**进行微调. 这里展示可直接运行的demo:
```shell
# Experimental environment: A100
# 50GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type cogvlm-17b-chat \
--dataset coco-en-2-mini \
```
[自定义数据集](../Instruction/自定义与拓展.md#-推荐命令行参数的形式)支持json, jsonl样式, 以下是自定义数据集的例子:
(支持多轮对话, 但总的轮次对话只能包含一张图片, 支持传入本地路径或URL)
```jsonl
{"query": "55555", "response": "66666", "images": ["image_path"]}
{"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]], "images": ["image_path"]}
```
## 微调后推理
直接推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true \
```
**merge-lora**并推理:
```shell
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx \
--merge_lora true
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/cogvlm-17b-chat/vx-xxx/checkpoint-xxx-merged \
--load_dataset_config true
```